|
I am a senior engineer at Cruise, working on 3D object detection, LiDAR/camera/radar fusion and deep learning for autonomous vehicles. Email / CV / Google Scholar / Github / LinkedIn |

|
|
My research work has been devoted to machine learning applied to computer vision, automated driving and biomedical informatics. |
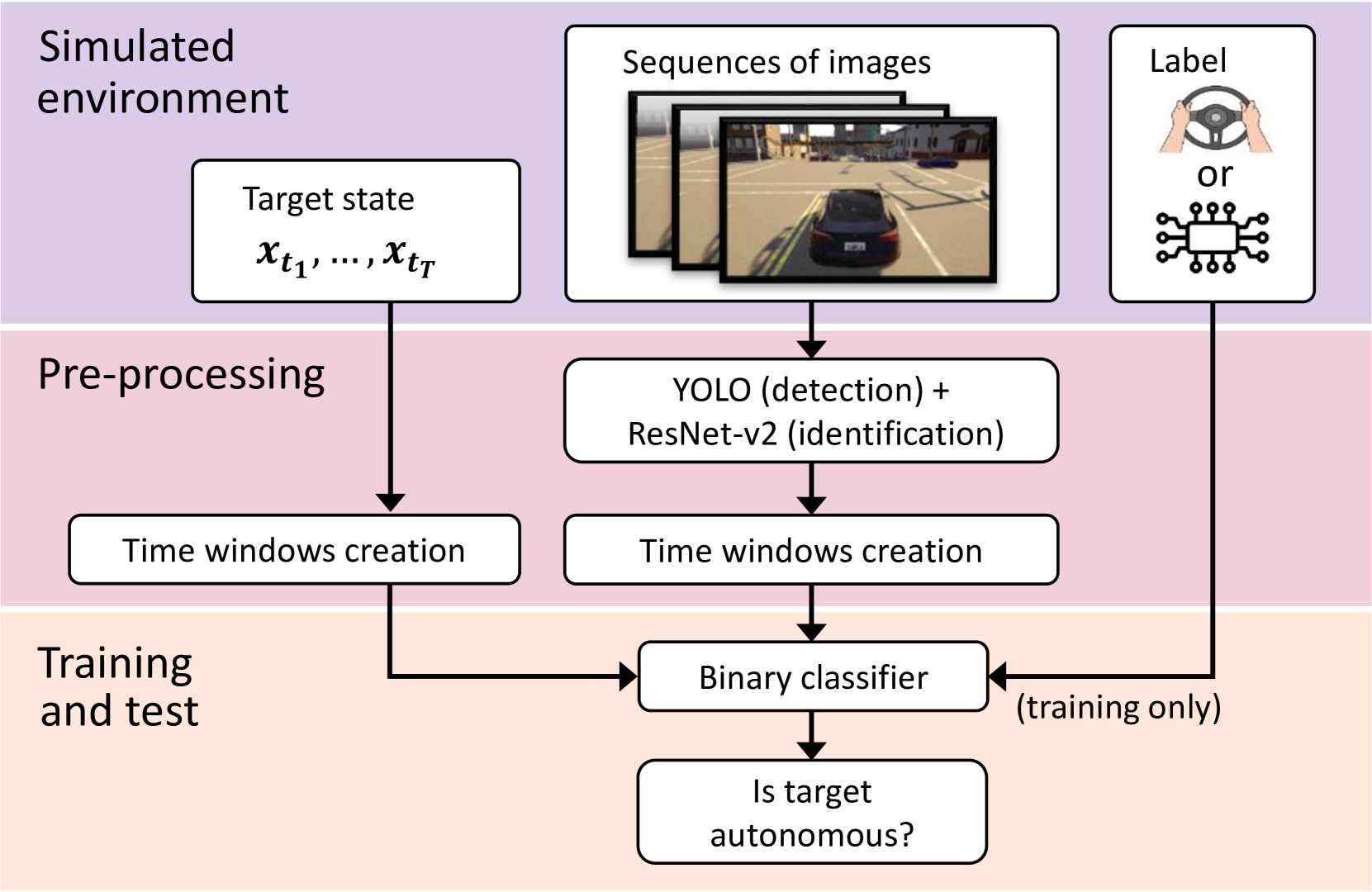 |
Fabio Maresca, Filippo Grazioli, Antonio Albanese, Vincenzo Sciancalepore, Gianpiero Negri, Xavier Costa-Perez IEEE International Conference on Robotics and Automation (ICRA), 2024 paper / dataset Can we detect autonomous vehicles from their behaviors in scenarios in which they share the road with human-driven ones? For this work, we created the NexusStreet dataset and made it publicly available. |
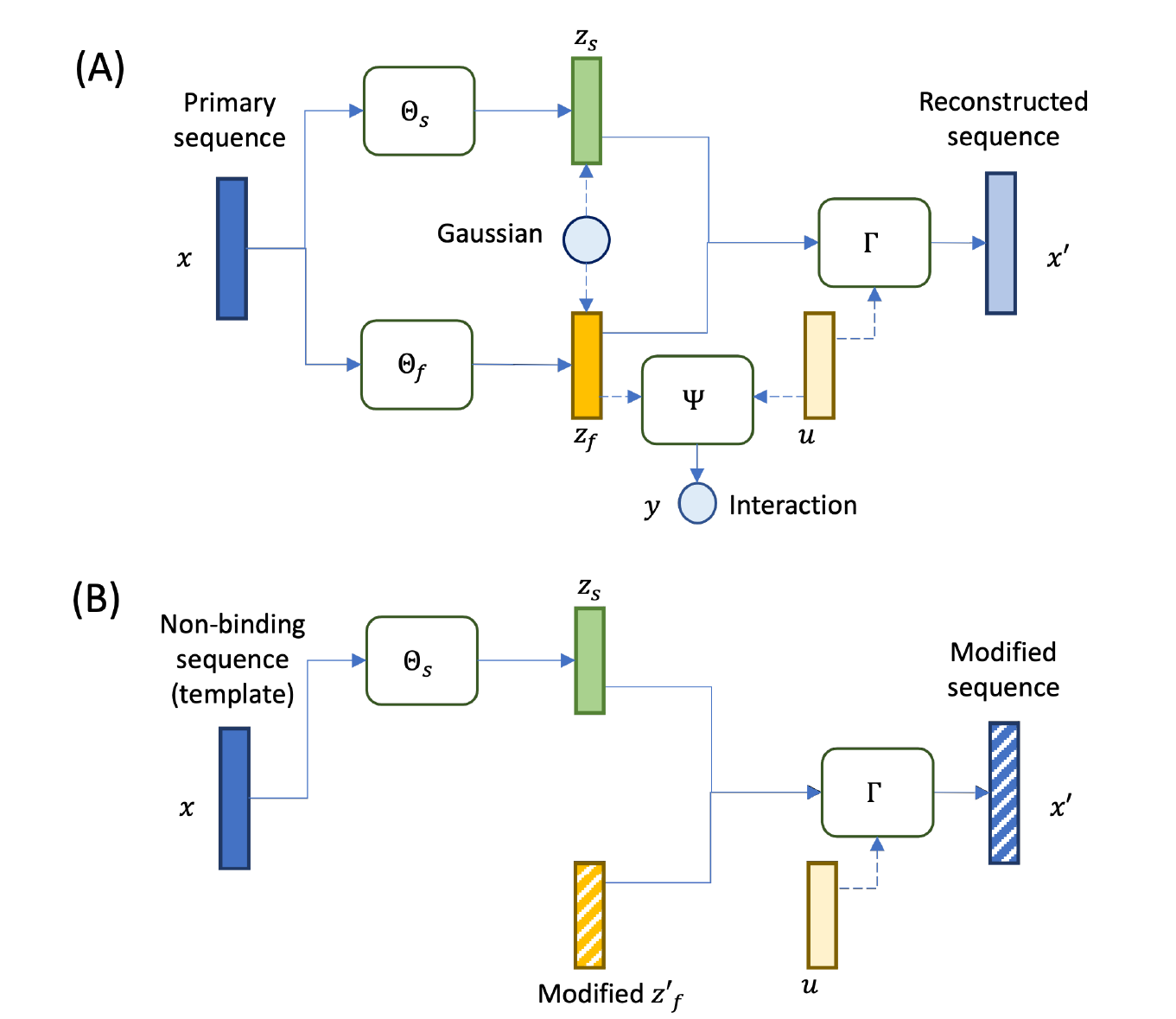 |
Tianxiao Li, Hongyu Guo, Filippo Grazioli, Mark Gerstein, Martin Renqiang Min Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS), 2023 paper / bibtex The interaction between T cell receptors (TCRs) and peptide antigens is critical for human immune responses. Designing antigen-specific TCRs represents an important step in adoptive immunotherapy. We propose a disentangled autoencoder, which can act as generative model for optimized TCR sequences. Optimized TCR sequences present enhanced binding affinity to a given peptide and preserve the backbone of a template TCR. |
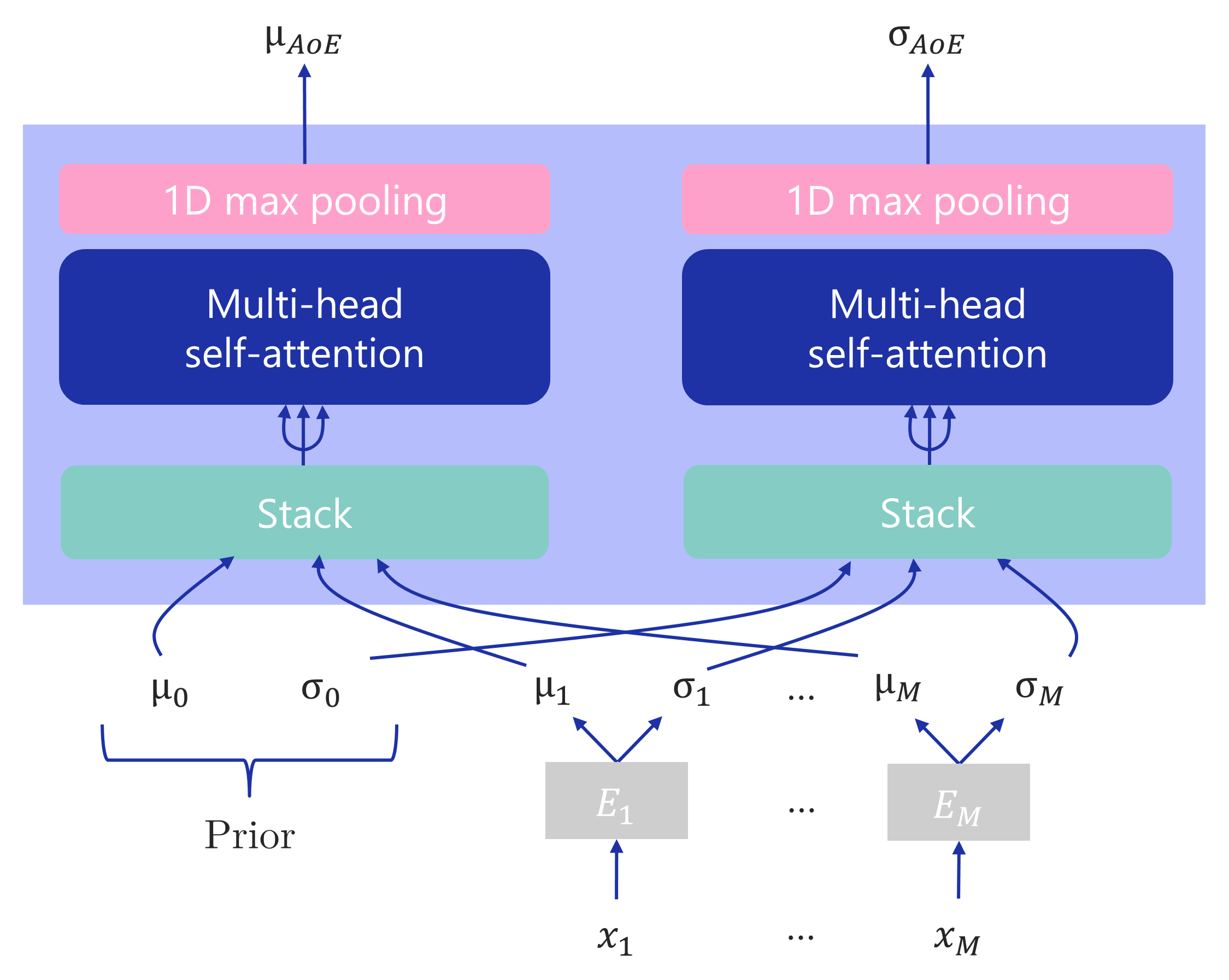 |
Filippo Grazioli, Pierre Machart, Anja Mösch, Kai Li, Leonardo V. Castorina, Nico Pfeifer, Martin Renqiang Min Bioinformatics, 2022 paper / bibtex / code A multi-sequence variational method for binding prediction between T-cell receptors (TCRs) and peptides presented on cells. We present a multi-sequence generalization of Variational Information Bottleneck (VIB) (Alemi et al., 2016) and call it Attentive Variational Information Bottleneck (AVIB). AVIB leverages multi-head self-attention (Vaswani et al., 2017) to implicitly approximate a posterior distribution over latent encodings conditioned on multiple input sequences. |
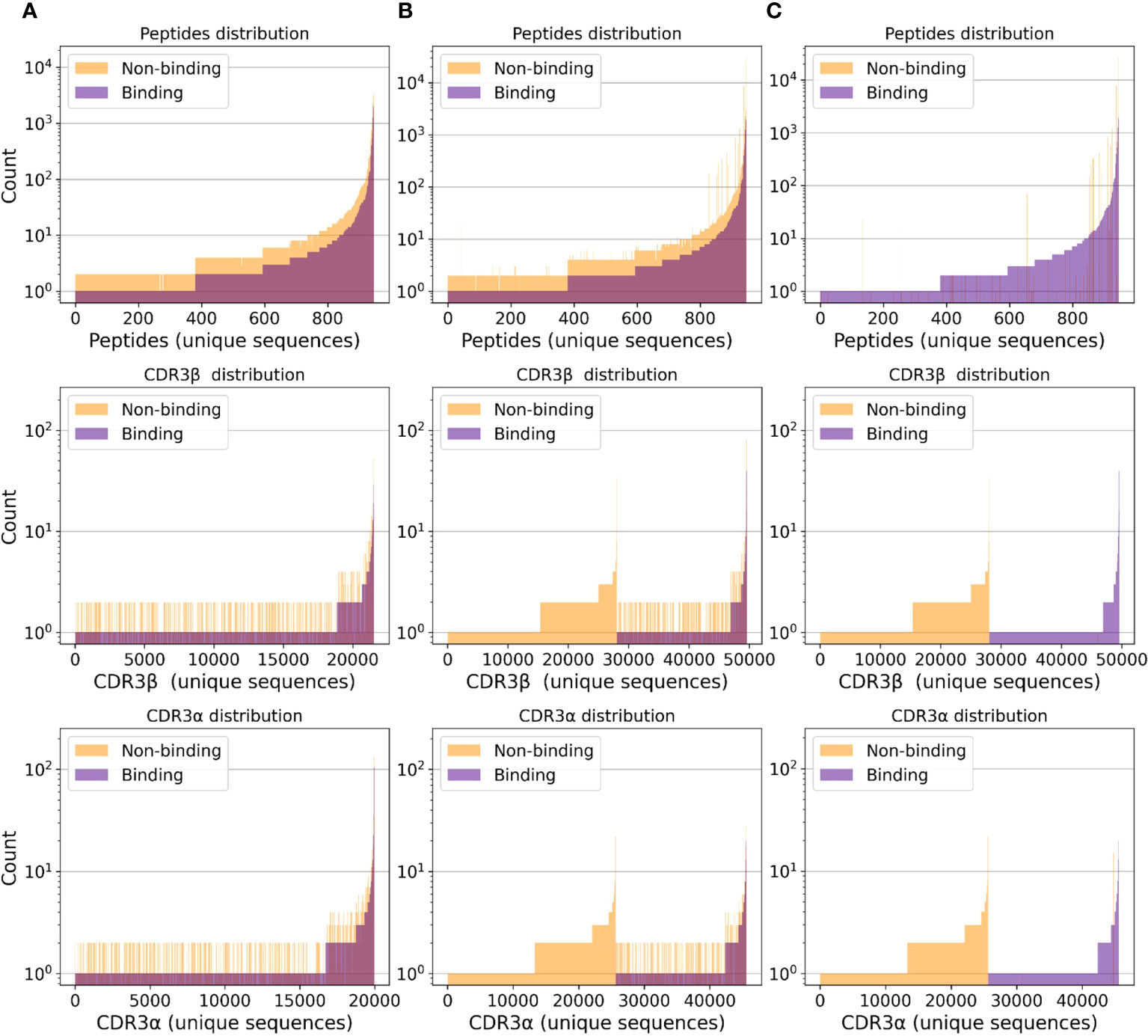 |
Filippo Grazioli, Anja Mösch, Pierre Machart, Kai Li, Israa Alqassem, Timothy J. O'Donnell, Martin Renqiang Min Frontiers in Immunology, 2022 paper / bibtex / code / dataset Here, we investigate the generalization capabilities of current deep-learning-based TCR binding predictors, i.e. models that predict the interaction of T cell receptors (TCRs) and peptide-MHC complexes presented on cells. We create a dataset, named TChard, including samples from IEDB, VDJdb, McPAS-TCR, and the MIRA set, as well as negative samples from both randomization and 10X Genomics assays. Our results show that modern deep learning methods fail to generalize to unseen peptides. |
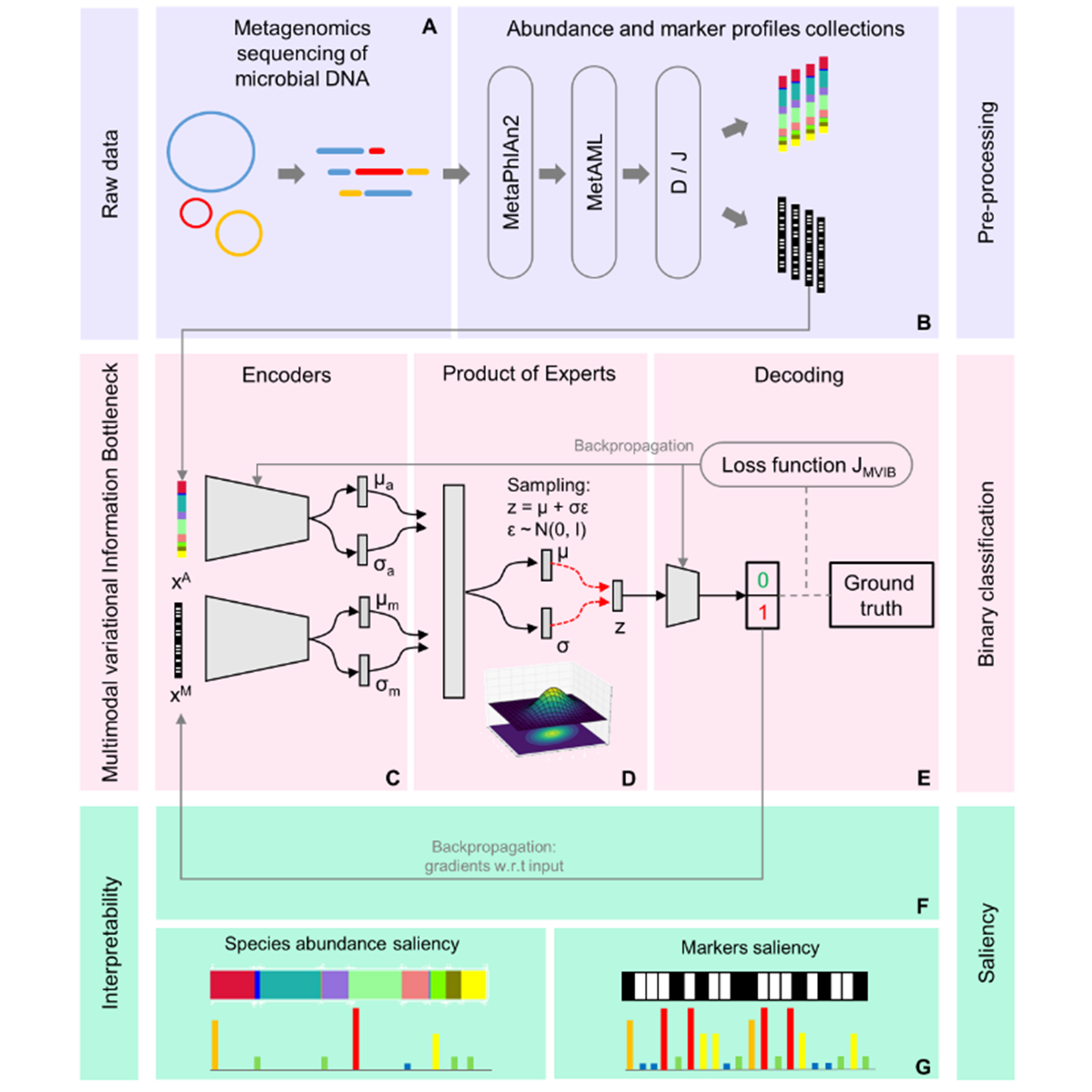 |
Filippo Grazioli, Raman Siarheyeu, Israa Alqassem, Andreas Henschel, Giampaolo Pileggi, Andrea Meiser PLOS Computational Biology, 2022 paper / bibtex / code A multimodal learning model derived from the theory of the information bottleneck. By looking at a patient's gut microbiome, we predict if they are affected by a certain disease. |
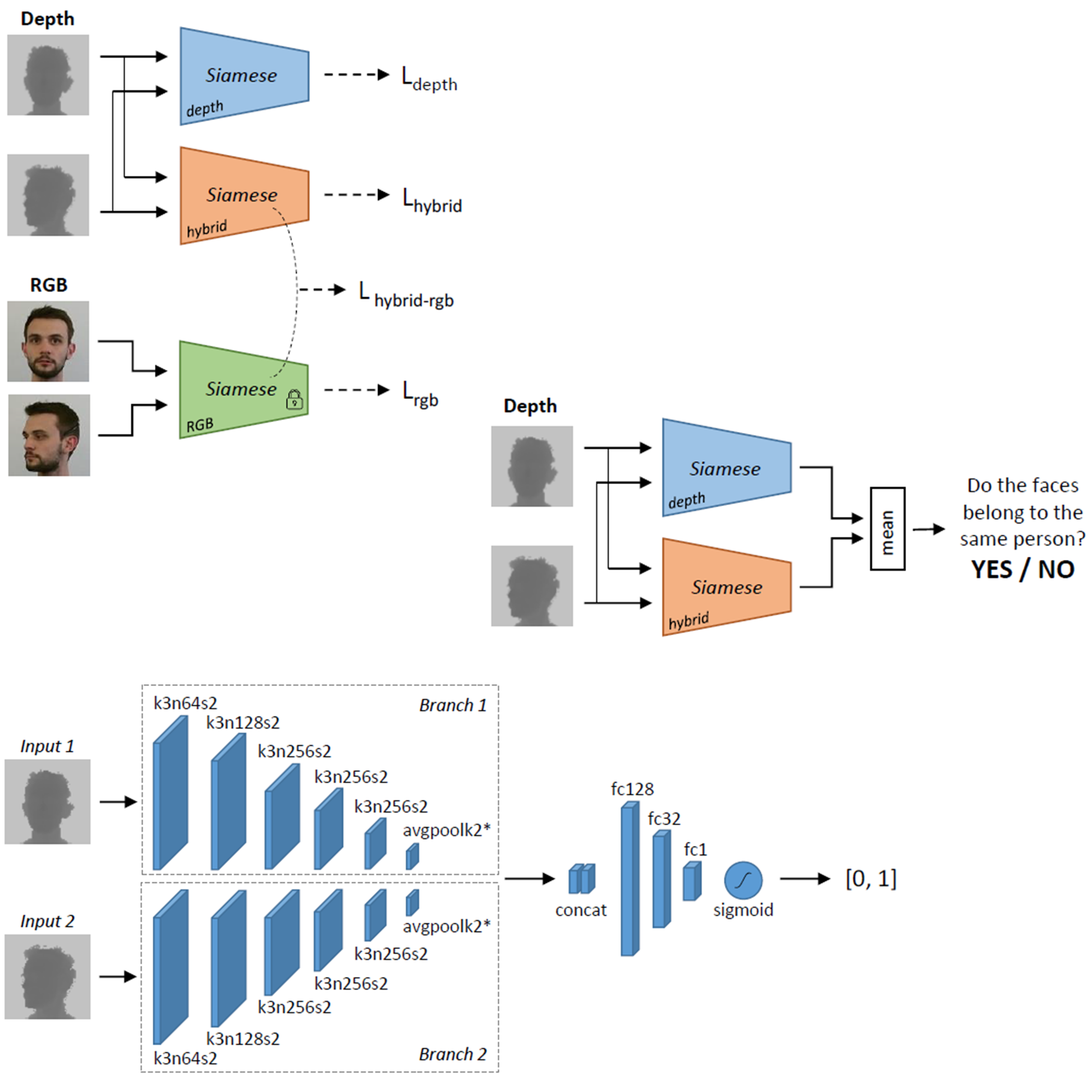 |
Guido Borghi, Stefano Pini, Filippo Grazioli, Roberto Vezzani, Rita Cucchiara The British Machine Vision Conference (BMVC), 2018 paper / bibtex / video A deep Siamese architecture for depth-based face verification. Leveraging privileged information learning, the model relies only on depth images, hallucinating the color information. |
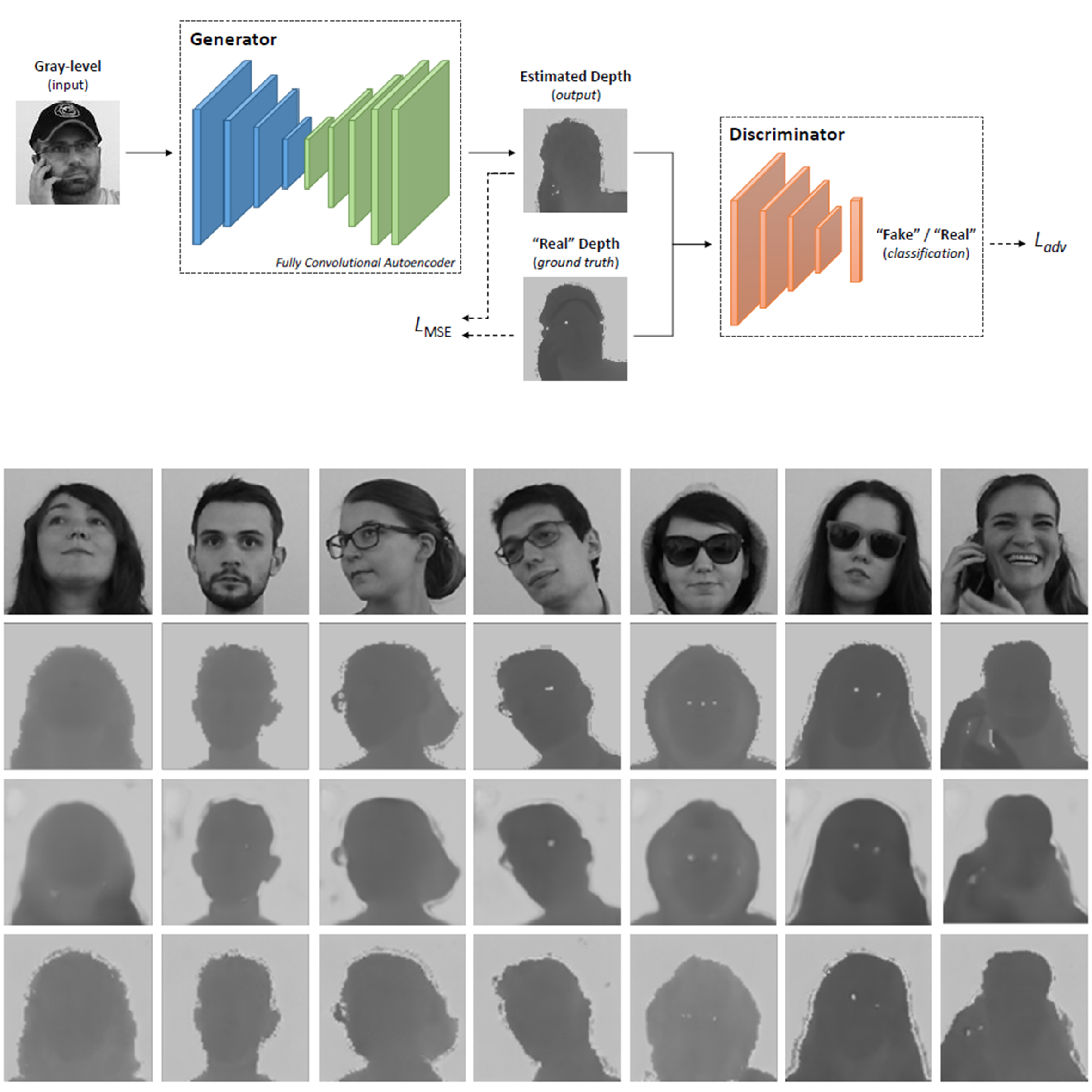 |
Stefano Pini, Filippo Grazioli, Guido Borghi, Roberto Vezzani, Rita Cucchiara International Conference on 3D Vision (3DV), 2018 arXiv / bibtex / video A conditional Generative Adversarial Network (GAN) for facial depth map estimation from monocular intensity images. |
|
|
Nicolas Daniel Herzberger, Gudrun Mechthild Irmgard Voß, Fabian Becker, Filippo Grazioli, Eugen Altendorf, Yigiterkut Canpolat, Frank Flemisch, Maximilian Schwalm International Conference on Applied Human Factors and Ergonomics (AHFE), 2018 paper / bibtex A model of control distribution between users and the automated systems. Objective driving data and eye-tracking parameters are used to estimate the model’s accuracy. |
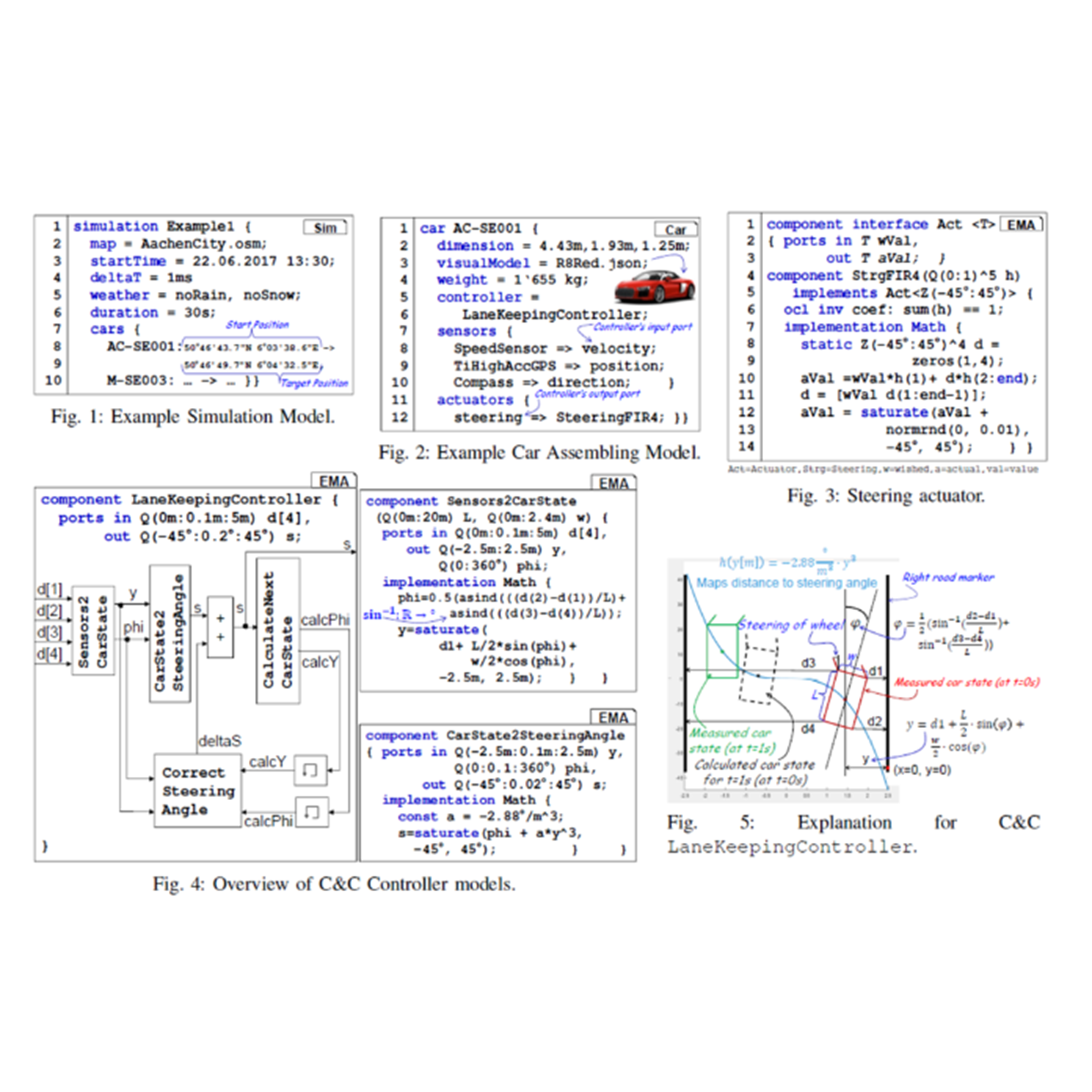 |
Filippo Grazioli, Evgeny Kusmenko, Alexander Roth, Bernhard Rumpe, Michael von Wenckstern International Conference on Model Driven Engineering Languages and Systems (MODELS), 2017 paper / bibtex / video A simulator that combines the benefits of both high-level and low-level simulators to execute component and connector models. The simulator allows to include new sensors, actuators and control systems. |
|
WO2023139031 (A1) - METHOD AND SYSTEM FOR PREDICTING TCR (T CELL RECEPTOR)-PEPTIDE INTERACTIONS WO2023193935 (A1) - METHOD AND SYSTEM FOR PREDICTING GENE EXPRESSION PERTURBATIONS WO2023138755 (A1) - METHODS OF VACCINE DESIGN WO2023072421 (A1) - SYSTEM AND METHOD FOR INDUCTIVE LEARNING ON GRAPHS WITH KNOWLEDGE FROM LANGUAGE MODELS WO2022242886 (A1) - A METHOD AND SYSTEM FOR PREDICTING A PHENOTYPIC FEATURE OF A HOST BASED ON A MICROBIOME OF THE HOST IT201800008237 (A1) - Sistema e metodo di autenticazione di persone in ambienti a limitata visibilità |
|
Website template by Jon Barron. |